The present paper reports about our experiences of conscious integration of durational knowledge into ASR based on standard HMM (non-HSMM). In Sect. 2 analyses will be given of the durational behaviour of the HMM and it will be revealed that even the simplest linear HMMs provide rich possibilities in modelling the phonetic segmental duration. Theoretical relations will be given between the HMM parameters and the durational pdf (dpdf) that the HMM governs. In Sect. 3 we will report about ways to integrate the constraints of segmental duration into the Baum-Welch ML training procedure and we will give results of improving the recognition and automatic segmentation performance using monophone HMMs. In Sect. 4 analyses of context-dependent duration statistics, using the TIMIT database, will be briefly discussed. In Sect. 5, proposals and an actual implementation will be presented to integrate the context-dependent duration models into a post-processing process of our monophone-based recogniser. In the final section, future research based on the experience obtained in this work is pointed out.
2. dpdf of standard hmm
2.1. Obtaining the dpdf of the whole HMM
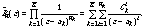 (1)
(1)
 states may have the same selfloop probabilities
states may have the same selfloop probabilities
 (the locations of these equal selfloops can be arbitrary). The coefficients
(the locations of these equal selfloops can be arbitrary). The coefficients
 in the right-hand side can be obtained by partial fraction decomposition. Each
summation term has a simple dpdf form in the d-domain, i.e. a negative
binomial:
in the right-hand side can be obtained by partial fraction decomposition. Each
summation term has a simple dpdf form in the d-domain, i.e. a negative
binomial:
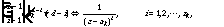
 denotes z-transformation. One can then inversely z-transform the
terms in (1) back to the d-domain and then sum them to get the dpdf. In
general such dpdf has a complicated form, especially for large number K
of different subsets. For instance, for a cascade of 10 states in 4 subsets of
1, 2, 3 and 4 states with equal selfloop probabilities, respectively, the
lowest-order binomial has 54 terms in the numerator of its coefficient. So we
will not print it here. The general dpdf is
denotes z-transformation. One can then inversely z-transform the
terms in (1) back to the d-domain and then sum them to get the dpdf. In
general such dpdf has a complicated form, especially for large number K
of different subsets. For instance, for a cascade of 10 states in 4 subsets of
1, 2, 3 and 4 states with equal selfloop probabilities, respectively, the
lowest-order binomial has 54 terms in the numerator of its coefficient. So we
will not print it here. The general dpdf is
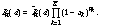
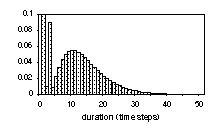
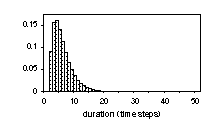
2.2. Analysis of whole-model dpdf
 ,
selfloop probability
,
selfloop probability
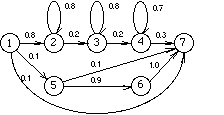
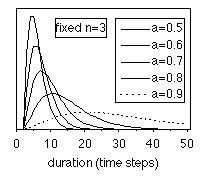
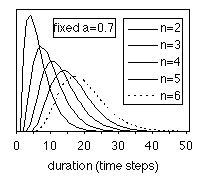
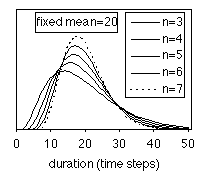
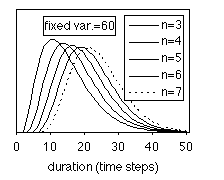
 and length n of linear models (single path), which are also shown in Fig
2 for the even simpler case of all-equal selfloop probability (the right-most
equalities in the formula). It can be seen that even such a simple linear model
provides rich possibilities in modelling segmental duration, usually having a
binomial-like shape. Proper values of the parameters should be chosen in order
to get the actual fit, since the parameters still allow for a lot of freedom.
and length n of linear models (single path), which are also shown in Fig
2 for the even simpler case of all-equal selfloop probability (the right-most
equalities in the formula). It can be seen that even such a simple linear model
provides rich possibilities in modelling segmental duration, usually having a
binomial-like shape. Proper values of the parameters should be chosen in order
to get the actual fit, since the parameters still allow for a lot of freedom.
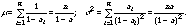
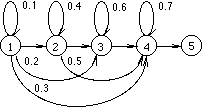
3. ml-training constrained with durational statistics
 2 of all the phones in the
system are collected and they together define the possible n for each
monophone HMM [7]:
2 of all the phones in the
system are collected and they together define the possible n for each
monophone HMM [7]:
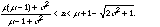
 as extra constraints are
as extra constraints are
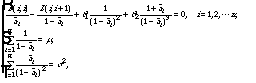
 need to be modified. The fitting situation is shown for two example phones in
Table 1. Durational statistics are collected from the whole TIMIT data (for
further details about this constrained training see [7]). The TIMIT training
set was used to train the 50 monophone HMMs with 3 Gaussians per state, a
diagonal covariance matrix, and n chosen as above. Table 2 shows
word-correct score improvements in both recognition and segmentation.
need to be modified. The fitting situation is shown for two example phones in
Table 1. Durational statistics are collected from the whole TIMIT data (for
further details about this constrained training see [7]). The TIMIT training
set was used to train the 50 monophone HMMs with 3 Gaussians per state, a
diagonal covariance matrix, and n chosen as above. Table 2 shows
word-correct score improvements in both recognition and segmentation.
pho original modifi modelled modelled
ne data ed + c
n
y 8.3 4.4 3.4 4 14. 6.4 8.3 3.4
4 0 9 94 8 4 9
z 10. 3.9 5 12. 4.5 10. 3.9
51 1 59 6 51 1
no constraint with duration
constraint
recognitio 80.61% 86.83% (84.41%)
n (77.73%)
segmentati 83.48% 84.48%
on
4. analysis of context-dependent durational statistics
factor: levels
R speaking rate 0: fast 1: average
2: slow
S stress (of 0:not 1:primary 2:
vowels) second.
L syllable if S=0,1: 0:rest;
w location in word 1:final; 2:penul.
3:mono if S=2:
0:rest; 1:final;
2:penul.
L syl. location in if Lw=0: 0:rest if
u utterance Lw=1:
0:rest;1:final;
2:penul. if Lw=2:
0:rest;
2:penul. if Lw=3:
0:rest;1:final;
2:penul.
5. integration of CD-duration models in post-processing
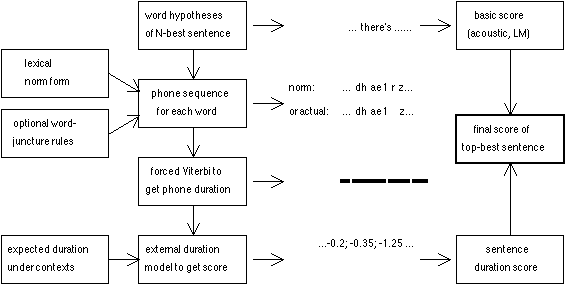
5.1. Word-juncture modelling
input output cl k cl cl t t.cl t
5.2. Duration score
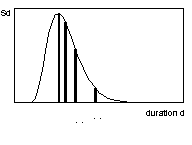
 (Fig. 4). These are the duration for maximum point
(Fig. 4). These are the duration for maximum point
 of
of
 for phone i, the CD duration mean
for phone i, the CD duration mean
 ,
the duration normalised
,
the duration normalised
 over the utterance transcription, and the actual duration
over the utterance transcription, and the actual duration
 .
Two differences are used for relative duration shifts:
.
Two differences are used for relative duration shifts:
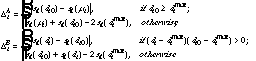
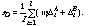
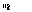 )
of
)
of
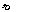 and the score of the utterance obtained in the N-best recognition
process.
and the score of the utterance obtained in the N-best recognition
process.
5.3. Re-scoring
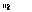 .
Experiments on the whole set of 1344 utteranes were not yet performed, but it
has to be expected that the word-correct score for the whole set will only
decrease after durational re-scoring with the current algorithm.
.
Experiments on the whole set of 1344 utteranes were not yet performed, but it
has to be expected that the word-correct score for the whole set will only
decrease after durational re-scoring with the current algorithm.
6. discussion
The experience in this work shows a possibility to integrate long-term speech features into the frame-level-based HMM technique. Integrating context-dependent information (of e.g. duration or pitch) in the last step of post-processing provides a simple system structure, and has the advantage of being able to correct any modelling errors that might have been made by the statistical modelling of other system components, no matter how "perfect" these components are designed.
7. REFERENCES
- 1. Lee, K.-F. Automatic speech recognition: the development of the Sphinx system, Kluwer Academic Publishers, Boston, 1989.
- 2. Levinson, S. E., "Continuous variable duration hidden Markov models for automatic speech recognition", Computer Speech and Language, 1(1), 1986, pp 29-45.
- 3. Press, W.H., Flannery, B.P., Teukolsky, S.A. & Vetterling, W.T. Numerical recipes in Pascal, Cambridge Univ. Press, 1989.
- 4. Mitcell C., Harper, M. & Jamieson, L "On the complexity of explicit duration HMM's", IEEE Transactions on Speech and Audio Processing, 3(3), 1995, pp 213-217.
- 5. Papoulis, A. Probability & statistics, Prentice-Hall, Inc., Englewood Cliffs, NJ, 1990.
- 6. Pols, L.C.W., Wang, X. & ten Bosch, L.F.M. "Modelling of phone duration (using the TIMIT database) and its potential benefit for ASR", presented to Speech Comm.
- 7. Wang, X. Integrating knowledge on segmental duration in HMM-based continuous speech recognition, Ph.D. thesis, University of Amsterdam, in preparation.